Persisting Entities
To persist your domain model into the database you use object-relational mapping (ORM), which is the basis for JPA. ORM specifies how sets of Java objects, including references between them, are mapped to rows and columns in database tables.
The term impedance mismatch refers to the differences in the OO and relational paradigms and difficulties in application development that arise from these differences. The persistence layer where the domain model resides is where the impendence mismatch is usually the most apparent. The root of the problem lies in the differing fundamental objectives of both technologies. Java objects hold references to other objects to save us from space efficiency concerns in implementing domain models with a high degree of conceptual abstraction. The JVM also offers the luxury of inheritance and polymorphism that does not exist in the relational world, rich domain model object includes behavior (methods) in addition to attributes (data instance variables). Databases tables on the other hand only, inherently encapsulate only rows, columns and constraints and not business logic. The table below summarizes some of the mismatches between object and relational worlds.
OO Model (Java) |
Relation Model |
| Object, Classes | Table, rows |
| Attributes, properties | Columns |
| Identity | Primary Key |
| Relationship/reference to other entity | Foreign Key |
| Inheritance/polymorphism | Not supported |
| Methods | Indirect parallel to SQL logic, stored procedures, triggers |
| Code is portable | Not necessarily portable, depending on vendor |
The most basic persistence layer for a Java application could consist of saving and retrieving domain objects using the JDBC API directly.
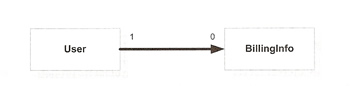
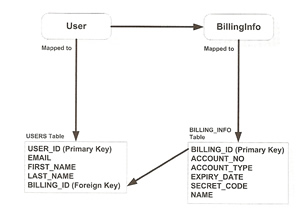
One-to-One relationships between entities make a great deal of sense in the domain-modeling world, The example below, the User and BillingInfo objects represents two logically separate concepts in the real world that are bound by a one-to-one relationship, it also does not make much sense for a BillingInfo object to exists without an associated User. The relationship could be unidirectional from User to BillingInfo
| The code | public class User { protected String userId; protected String email; // Object reference for one-to-one relationship protected BillingInfo billings; } public class BillingInfo { protected String creditCardType; protected String creditCardNumber; ... } |
The above example implies that the database tables storing the data to mirror the Java implementation, thus two tables would be created USERS and BILLING_INFO, with the billing object reference in the User object translated into a foreign key to the BILLING_INFO tables key in the USERS table. However this does not make much sense in the relational world, since the objects are merely expressing a one-to-one relationship, normalization would dictate that the USERS and BILLING_INFO tables be merged into one. This would eliminate the almost pointless BILLING_INFO table and the redundant foreign key in the USERS table. The extended USERS table would look like below
| Users table | USER_ID NOT NULL, PRIMARY KEY NUMBER |
The example above means that the persistence layer mapping code would have to pull out data from both USERS and BILLING_INFO tables and storing in the columns of the combined USERS table, you could compromise the domain model to make it fit the relational data model but this is not a desired approach, you could make the BillingInfo object a embedded object since you do not want to a have a separate identity and want to store the data in the USERS table.
In the general sense the term Object-Relational Mapping means any process that can save an object into a relational database, ORM uses metadata to tell the high-level API which table a set of Java objects are going to be saved into. ORM free you from the repetitive "plumbing" code of JDBC and the large volume of complicated handwritten SQL code, the EJB 3 persistence layer generates JDBC and SQL code on your behalf. The persistence layer is also capable of automatically generating code optimized to your database platform from your database-neutral configuration data, switching databases becomes a snap, this portability is an appealing feature of the EJB 3 persistence API.
In this section we cover the following annotations
Here is an example using some of the above annotations
| Basic Entity | @Entity |
The entity above covers all the annotations we want to look at, first we take a look at the @Table annotation which is actually optional
| @Table definition | @Target(TYPE) @Retention(RUNTIME) public @interface Table { String name default ""; String catalog() default ""; String schema() default ""; UniqueConstraint[] uniqueConstraints() default {}; } Note: name - the name of the table, if omitted it is assumed to be the same as the name of the entity catalog - a high level abstraction for organizing schemas schema - this is regarding the automatic schema generation, for entities that do not already exists uniqueConstraints - specifies unique constraints on table columns (used only when autocreation is enabled) |
Most production environments will not use the automatic generation, mainly has you will create you master data tables separately.
The @Column annotation maps a persisted field or property to a table column, again this is optional, most the the above in the example are pretty self explaining, sometimes you need to explicitly specify which table the persisted column belongs to (you do this using the @SecondaryTable annotation) then specify the table with the @Column annotation. You can use either field-based or property-based (set and get methods). The @Column definition has many parameters
| @Column definition | @Target({METHOD,FIELD}) @RETENTION(RUNTIME) public @interface Column { String name default ""; boolean unique() default false; boolean nullable() default true; boolean insertable() default true; boolean updateable() default true; String columnDefinition() default ""; String table() default ""; int length() default 255; int precision() default 0; int scale() default 0; } Notes: name - the SQL name of the column unique - does the column have a unique constraint nullable - supports null columns (true for unique columns) insertable - True if column is inserted on a create call updatable - True if the column is updated when the field is modified columnDefinition - SQL to create column in a CREATE TABLE table - specified if the column is stored in a secondary table length - the size of the column precision - specifies the precision of a decimal field scale - specifies the scale of a decimal column |
Enumerated types were introduced in Java 5.0, they effectively define the data type in a field, the field can only have one of the values listed in the enumeration. Like an array each element of the enumeration is associated with an index called the ordinal, looking at the below example UserType.SELLER has an ordinal of 0.
| Enumeration | public enum UserType {SELLER, BIDDER, CSR, ADMIN}; |
The Java Persistence API supports two options through the @Enumerated annotation,
| Enumerated as a ordinal | @Enumerated(EnumType.ORDINAL) Note: this is the default if the @Enumerated annotation is omitted |
| Enumerated as a String | @Enumerated(EnumType.String) |
You have the ability to store very large data as either binary large objects (BLOB) and character large object (CLOB) types, you use the @Lob annotation for both and is determined by its type. If the data is of type char[] or String, the persistence provider maps the data to a CLOB column, otherwise it maps it to a BLOB.
| Mapping BLOBs or CLOBs | @Lob @Basic(fetch=FetchType.LAZY) protected byte[] picture; |
The @Basic annotation can be marked on any attribute with direct-to-field mapping, the example above causes the BLOB or CLOB data to be loaded from the database only when it is first accessed, postponing of loading of entity data from the database is known as lazy loading.
Most databases support a few different temporal data types with different granularity levels corresponding to DATE, TIME, TIMESTAMP. The @Temporal annotation specifies which of these data types we want to map a java.util.Date or java.util.Calendar persistent data type to.
| @Temporal | @Temporal(TemporalType.DATE) Note: the default if the annotation is not used is TIMESTAMP |
Embeddable objects acts primarily as a convenient data hold for entities and has no identity of its own, it shares the identity of the entity class it belongs to.
@Embedded/@Embeddable |
@Table(name="USERS") Note: the address data will be held in the users table in the database |
| Using the override attribute | @Embedded @AttributeOverrides({@AttributeOverride( name="postcode" column=@Column(name="POST_CODE"))}) protected Address address; Note: here we tell the provider to resolve the embedded "postcode" field to the POST_CODE column |
I mentioned above using secondary tables that may be used when accessing an entity, the @SecondaryTable annotation enables us to derive entity data from more than one table, the definition is below
| @SecondaryTable definition | @Target({TYPE}) @Retention(RUNTIME) public @interface SecondaryTable { String name(); String catalog() default ""; String schema() default ""; PrimaryKeyJoinColumn[] pkJoinColumns() default {}; UniqueConstraints[] uniqueConstraints() default {}; } Notes: name - the name of the table catalog - the catalog of the table schema - the schema of the table PrimaryKeyJoinColumn - the columns that are to join with the primary table UniqueConstraints - unique constraints that are placed on the table |
| Example | @Entity @Table(name="USERS") @SecondaryTable(name="USER_PICTURES", pkJoinColumn=@PrimaryKeyJoinColumn(name="USER_ID")) public class User implements serializable { ... @Column(name="PICTURES", table="USER_PICTURES") @Lob @Basic(fetch=FetchType.LAZY) protected byte[] picture; ... } |
Primary keys enforce uniqueness on columns, there are two types of key
There are aa number of ways to generate primary keys
All three strategies are supported by the @GeneratedValue annotation and switching is as easy as changing the configuration.
| Identity columns as generators | @Id Note: we are presuming that an identity constraint exists on the USERS.USER_ID column |
| Database sequences as generators | # Oracle sequence # Using the sequence generator Note: All generators are shared among all entities in the persistence module |
| Sequence tables as generators | # generator table # prepare the table # Create the TableGenerator # Using the sequence generator table Note: the table can hold many sequences, all with different names and values |
| Default primary key generation strategy | @Id Note: the provider will decide the best strategy for the underlying database, so consult the JPA provider docs on what it will choose. |
In the domain model subject I discussed the translating relationships from the OO world to the database world. I will now go into a bit more detail on the EJB 3 annotations that are used.
One-to-one relationships are mapped using primary/foreign key association, depending on where the foreign key resides the relationship could be implemented in two different ways using either @JoinColumn (@JoinColumns if more than one foreign key) or @PrimaryKeyJoinColumn. If the underlying table for the referencing entity is the one containing the foreign key to the table to which the referenced "child" entity is mapped, you can map the relationship using the @JoinColumn annotation.
| @JoinColumn | @Entity Note: the default foreign key value is: |
If the foreign key is in the table to which the child entity is mapped we use the @PrimaryKeyJoinColumn annotation
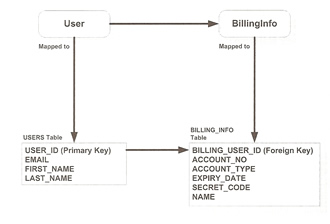
| @primaryKeyJoinColumn | @Entity @Table(name="USERS") public class User { @Id @Column(name="USER_ID") protected Long userId; ... @OneToOne @PrimaryKeyJoinColumn(name="USER_ID", referencedColumnName="BILLING_USER_ID") protected BillingInfo billingInfo; } @Entity @Table(name="BILLING_INFO") public class BillingInfo { @Id @Column(name="BILLING_USER_ID") protected Long userId; ... } |
One-to-Many (@OneToMany) and Many-To-One (@ManyToOne) relationships are the most common, this setup uses the same one-to-one relationships method, this is because both relation types are implemented as a primary-key/foreign-key association in the underlying database
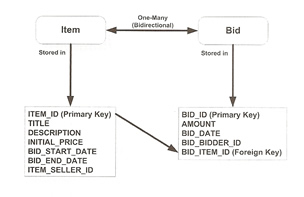
| @OneToMany/@ManyToOne | @Entity Note: In a bidirectional one-to-many relationship the owner of the relationship is the entity side that stores the foreign key - that is, the many side of the relationship. |
Remember to use a mappedBy element when using bidirectional relationships, otherwise the persistence provider will treat it as a unidirectional relationship.
You can also have a self-referencing relationship, again you use the @JoinColumn annotation
| self-referencing | @Entity @Table(name="CATEGORIES") public class Category implements Serializable { @Id @Column(name="CATEGORY_ID") protected Long categoryId; ... @ManyToOne @JoinColumn(name="PARENT_ID", referencedColumnName="CATEGORY_ID") Category parentCategory; ... } |
A many-to-many relationship in the database is implemented by breaking it down into two one-to-one relationships stored in an association or join table. An association or join table allows you to indirectly match primary keys from either side of the relationship by storing arbitrary pairs of foreign in a row.
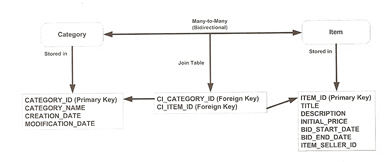
We use the @JoinTable annotation to archive this
| Many-To-Many | @Entity @Table(name="CATEGORIES") public class category implements Serializable { @Id @Column(name="CATEGORY_ID") protected Long categoryId; // joinColumns - describes the owning relationship // inverseJoinColumns - describes the subordinate relationship @ManyToMany @JoinTable(name="CATEGORY_ITEMS", joinColumns(name="CI_CATEGORY_ID", referencedColumnName="CATEGORY_ID"), inverseJoinColumns= @JoinColumn(name="CI_ITEM_ID", referencedColumnName="ITEM_ID" ) ) protected Set<Item> item; ... } @Entity @Table(name="ITEMS") public class Item implements Serializable { @Id @Column(name="ITEM_ID") protected Long itemId; ... @ManyToMany(mappedBy="item") protected Set<Category> categories; ... } |
There are difficulties in mapping OO inheritance into relational databases, the three strategies used are
In all three cases we use the @Inheritance annotation which tries to isolate strategy specific setting into the configuration, for our example we created several user types, including sellers and bidders, we also introduced a User superclass common to all user types. The below diagram shows how this looks
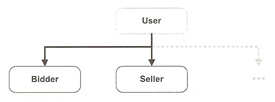
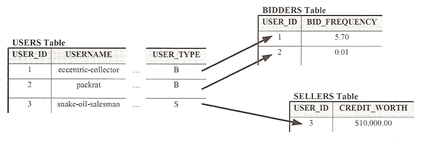
We first look at the single-table strategy, all classes in the inheritance hierarchy are mapped to a single table. Different objects in the OO hierarchy are identified using a special column called a discriminator column. The discriminator column contains a value unique to the object type in a given row.

The USERS table contains data common to all users such as USER_ID and USERNAME, Bidder specific data such as BID_FREQUENCY and seller specific data such as CREDIT_WORTH, its all contained in a single table, records 1 and 2 contain bidder records and record 3 contains a sellers record. The persistence provider maps each user type to the table by storing persistent data into the relevant mapped columns, setting the USER_TYPE correctly and leaving the rest of the values NULL.
| Inheritance mapping using a single table | # User @Entity @Table(name="USERS") @Inheritance(strategy=InheritanceType.SINGLE) @DiscriminatorColumn(name="USER_TYPE", discriminatorType=DiscriminatorType.STRING, length=1) public abstract class User ... # Seller @Entity @DiscriminatorValue(value="S") public class Seller extends User ... # Bidder @Entity @DiscriminatorValue(value="B") public class Bidder extends User ... |
The problems with the single-table strategy is that there could be many NULL column values which could be significant if you have few thousand lines, the other problem is that if you wanted to enforce a NOT NULL constraint for the bidder as the column would contain seller records which could contain NULL values.
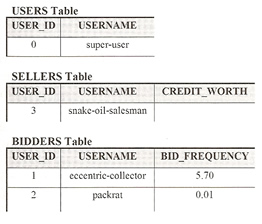
Joined-table strategy avoids the above problems because it uses one-to-one relationships to model OO inheritance, the joined-table strategy involves creating separate tables for each entity in the OO inheritance and relating direct descendents in the hierarchy with one-to-one relationships.
In this strategy the parent table contains columns common to all user types, the child table contains columns specific to the entity type (either bidder or seller in this case).
| Inheritance mapping using joined tables | # User @Entity @Table(name="USERS") @Inheritance(strategy=InheritanceType.JOINED) @DiscriminatorColumn(name="USER_TYPE", discriminatorType=DiscriminatorType.STRING, length=1) public abstract class User ... # Seller @Entity @DiscriminatorValue(value="S") @PrimaryKeyJoinColumn(name="USER_ID") public class Seller extends User ... # Bidder @Entity @DiscriminatorValue(value="B") @PrimaryKeyJoinColumn(name="USER_ID") public class Bidder extends User ... |
Although this solves the above problems, from a performance perspective it is worse than a single-table strategy, because it requires the joining of multiple tables for polymorphic queries.
The last strategy is the table-per-class strategy, this is the simplest inheritance strategy for you and me to understand, but it is the worst from a relational and OO standpoint. Both the superclass and the sub-classes are stored in there own table and no relationship exists between any of the tables.
| Inheritance mapping using the table-per-class strategy | # User @Entity @Table(name="USERS") @Inheritance(strategy=InheritanceType.TABLE_PER_CLASS) public abstract class User ... # Seller @Entity @Table(name="SELLERS") public class Seller extends User ... # Bidder @Entity @Table(name="BIDDERS") public class Bidder extends User ... |
This strategy does not have good support for polymorphic relations or queries because each subclass is mapped to its own table, when you want to retrieve entities over persistence provider you must use SQL UNION or retrieve each entity with a separate SQL for each subclass in the hierarchy. Because this is the hardest strategy to implement it has been made optional for the provider by the EJB 3 specification, we recommend that this strategy should be avoided.
Here ia summary table of what I discussed above
Feature |
Single Table |
Joined Tables |
Tables per Class |
| Table Support | One table for all classes in the entity hierarchy:
|
One for the parent class, and each subclass has a separate table to store polymorphic properties Mapped tables are normalized |
One table for each concrete class in the entity hierarchy |
| Use discriminator column | Yes | Yes | No |
| SQL generated for retrieval of entity hierarchy | Simple select | select clause joining multiple tables | One select for each subclass or union of select |
| SQL for insert and update | Single insert or update for all entities in the hierarchy | Multiple insert, update: one for the root class and one for each involved subclass | One insert or update for every subclass |
| Polymorphic relationship | Good | Good | Poor |
| Polymorphic queries | Good | Good | Poor |
| Support in EJB 3 JPA | Required | Required | Optional |