JBoss Clustering
JBoss enables you to simultaneously run your application on multiple application servers, requests can be load balanced across these servers and with stand server failures. Java EE does not specify any standards for how clustering services should work and every application server may implement a different solution. JBoss has made setting up a cluster very easy with minimal configuration, nodes can be added to the cluster automatically without configuration changes. JBoss also provides a sophisticated distributed cache that allows stateful components to replicate their states across multiple nodes in a cluster.
Clustering means running the same application on multiple application server instances simultaneously with each application server being aware of the other nodes in the cluster. Each node in the cluster must be able to replicate state or provide failover capabilities.
Load balancing is away of balancing incoming load or concurrent requests across multiple application server instances. The more nodes to load balance across the more application traffic can be handled. If a instance were to fail then the application traffic would still be handled but by fewer nodes. There are two types of load balancer
Load balancers basically make a single IP address for a cluster visible to clients, the load balancer maintains a map of internal IP addresses for each machine in the cluster, when a request comes in it rewrites the packet header and points it to a particular machine, the load balancer will distribute the packets evenly across all instances.
There are a number of different load balancing strategies, below are the three common types, others are available depending on what you use.
| random | sends client requests randomly to a server in the cluster |
| round-robin | sends client requests sequentially through the servers in the cluster |
| sticky-session | sends the first client request either via random or round-robin but once a connection is established with a particular server all subsequent requests will go to the same server, unless the server fails. |
There is a another load balancing solution using DNS (round-robin), there are a number of issues with using round-robin DNS
Clusters can be run on a single server (horizontal) or multiple servers (virtual), JBoss makes bringing up a cluster easy as it uses a feature called automatic discovery, this allows the cluster nodes to discover each other without having to configure them to know about each other. Web services and even JNDI can be clustered across all nodes within the cluster.
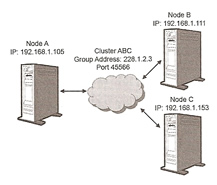
Automatic discovery means that a node can discover an existing cluster or create one itself, the first node in the cluster is the coordinator which means that it manages how other nodes subscribe to the existing cluster. The automatic-discovery features uses a group-communication mechanism known as a multicast - a method for forwarding information to a group of people where the sender only sends the message once and does not need to know the recipients, its a bit like the TV or a Radio, a signal is sent out and anyone who tunes in can receive the signal. The communication channel used for multicast communication is comprised of a multicast address (group address) and a multicast port. Group members send messages to this address and subscribe to receive messages that other have sent.
JBoss uses a tool called JGroups to enable peer-to-peer communication between nodes, it uses existing network infrastructure and protocols to transmit multicast messages, receivers can request retransmission of lost packets of data which makes it a reliable service. JGroups have the following features
A fault-tolerant clustered application is one that is highly available and can continue even if a node were to crash. There are two types of data that typically associated with a users session, session data and entity data. Session data is associated with a user and is owned by the node that the client is communicating with. Session data is maintained in memory by the application or through caching services enabled by the application server, HTTP sessions and SFSB are examples of this. Entity data is owned by the database, the master copy of the data is maintained in the database although many applications keep some of the entity data in an in-memory cache for better performance, EJB3 entities are examples of this.
JBoss uses a clustered cache that can replicate cached session data across nodes in the cluster, this is known as state replication. Replication can come in two types synchronous or asynchronous, synchronous can be slow as it makes the application wait until the state information is replicated thus it is dependent on the slowest node in the cluster as it has to write to all nodes. Asynchronous replication sends a response back to the client immediately before all the state information has been replicated across all nodes, obviously this model does not guarantee that the state of one request is replicated before subsequent requests are sent there is not a 100% guarantee of fault tolerance. There are many decisions to make on what one you choose and most of it will depend on costs and current infrastructure.
JBoss has two different methods to choose from
| Total Replication | ever node in a cluster is replicating state with every other node in the cluster, this called total state replication. each nodes keeps its own state and the state of every other node in the cluster, this means that large amounts of memory can be used also well as CPU cycles and network bandwidth. |
| Buddy Replication | state replication is replicated across only a subset of nodes you are buddies with, reducing the amount of memory, cpu and network traffic. If a node fails any node that a request fails over to is capable of retrieving the information from the buddy node. |
JBoss can invalidate entity data within a cache, because all the nodes point to the same database which holds the master copy of the entity data invalidating causes one node to send a message to the other node to let them know that they do not have the latest copy of the data and they should evict from their cache, thus when a request comes in it will read it from the database to obtain the latest copy. Invalidation messages are much smaller than replication messages thus reducing network traffic.
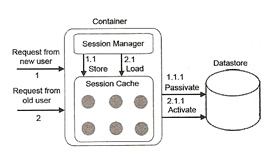
Some applications need to keep sessions open for long periods of time, but this means that memory is consume for greater periods even if the session is inactive. Session Passivation can be used to store inactive sessions to a secondary storage device (hard disk, database, etc). These sessions can then be activated if they are accessed again or purge if they timeout. One point to note is that there will be a pause when accessing the data again as the server will need to retrieve it from the storage that is was passivated to.
Now you have an idea what a cluster is lets set one up, I am going to setup a cluster on a windows laptop, both nodes will run on the same laptop, in the real world you would have multiple servers, which is easier to setup as you will not have network port clashes.
I am only going to explain the JBoss setup and leave you to setup you own network interfaces, etc. For the purposes of this example I will use two IP addresses 192.168.0.100 and 192.168.0.101.
Download the latest version of JBoss and copy to c:\jboss5 (I have a tutorial on JBoss installation), navigate into the server directory and copy all the directory twice: once to a directory called node1 and the other node2, you should have something like below

Open two console windows and run the below commands
| node 1 | ./run.sh -c node1 -b 192.168.0.100 -Djboss.messaging.ServerPeerID=1 |
| node 2 | ./run.sh -c node1 -b 192.168.0.101 -Djboss.messaging.ServerPeerID=2 |
| Testing | http://192.168.0.100:8080 http://192.168.0.101:8080 |
Now check the logfile and make sure the cluster started and believe it or not you have a cluster running, how easy/cool was that. From the logfile you will see a messages relating to DefaultPartition which means a cluster, having different DefaultPartitions means having different clusters, so you can create multiple clusters on the same network. Remember, all this happened because of the automatic discovery we looked at earlier.
Now lets create a EJB application and get it running in the cluster
| Remote Interface | import javax.ejb.Remote; @Remote public interface Counter { public void printCount(int messageNumber); } |
| Bean Code | import javax.ejb.Stateless; import org.jboss.ejb3.annotation.Clustered; @Stateless @Clustered public class CounterBean implements Counter { public void printCount (int countNumber) { System.out.println("Count: " + countNumber); } } |
When you compile the code don't forget to add the client/jbossall-client.jar in your classpath, create a EJB-JAR file and deploy it in server/xxx/deploy on both servers. A popular way to handle cluster deployments is to configure the deployment scanner so that each node points to a directory mounted on a network (NFS share).
Now build the client as below
| Client | import javax.naming.Context; import javax.naming.InitialContext; public class Client { public static void main(String[] args) throws Exception { InitialContext ctx = new InitialContext(); Counter s = (Counter) ctx.lookup("CounterBean/remote"); for (int i = 0; i < 100; i++) { s.printCount(i); Thread.sleep(1000); } } } |
| jndi.properties | java.naming.factory.initial=org.jnp.interfaces.NamingContextFactory java.naming.factory.url.pkgs=org.jboss.naming |
Compile the above code making sure you have the client/jbossall-client.jar file in your classpath. When the client starts it uses automatic discovery to find a JNDI server and then uses the JNDI server to obtain a remote interface (dynamic proxy) for a SLSB. The client simply calls the printCount() method on the dynamic proxy in a loop with a one second pause between calls. Each time the printCount() method is executed the dynamic proxy calls the server to execute the SLSB code.
Open consoles on each node and you should see that the messages send from the client are being load balanced across both nodes. Play around with this setup by bringing down one of the nodes, keep checking the log files so that you get to know what the cluster is doing. Remember, stateless applications only require load balancing in order to be fault tolerant.
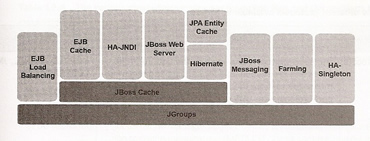
JBoss uses multicasting to enable automatic discovery and group communication within a cluster, the below picture shows the major clustering services JBoss uses. A number of services are built on top of JBoss cache, which in turn builds on top of JGroups.
Two of the main components in JGroups are the channel and the protocol stack, a channel provides a way for applications to connect and send messages to other members in the cluster. Messages go down the protocol stack and then up it (see below diagram). Each layer in the stack consists of a protocol, a protocol in JGroups is a component that can send, receive, modify, reorder, pass, drop a message.
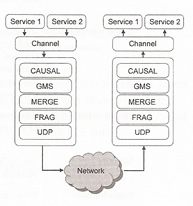
There are a number of different protocols that can be used within a channel
| Protocol Category | Description | Protocols |
| Transport Protocols | Transport protocols are found at the bottom of the stack and are responsible for sending and receiving messages from/to the network. | UDP, TCP, TUNNEL, JMS, LOOPBACK |
| Initial Membership Discovery | These services are used when a node is trying to establish initial membership, it either joins a cluster or creates a new one. | PING, TCPPING, TCPGOSSIP, MPING |
| Fragmentation and Merging | Used to split and resemble large packets | FRAG, FRAG2 |
| Reliable Message Transmission | makes sure that packets are sent in the correct order and that they have been received | CAUSAL, NAKACK, pbcast.NAKACK, SMACK, UNICAST, PBCAST, pbcast.STABLE |
| Group Membership | Notifies the cluster when a node joins, leaves or crashes. The MERGE protocol is used to unify groups that have been split. The VIEW_SYNC protocol causes group members to periodically synchronize their membership information. | pbcast.GMS, MERGE, MERGE2, VIEW_SYNC |
| Failure Detection | used to poll nodes within the cluster to make sure they are still alive | FD, FD_SIMPLE, FD_PING, FD_ICMP, FD_SOCK, VERIFY_SUSPECT |
| Security | adds a layer of security to JGroups | AUTH |
| State Transfer | used to transfer application state to a joining member of a group | pbcast.STATE_TRANSFER, pbcast.STREAMING_STATE_TRANSFER |
| Debugging | used for diagnostic, performance tuning and debugging | PERF_TP, SIZE, TRACE |
| Miscellaneous | COMPRESS protocol is used to compress and decompress packets, the FLUSH protocol is used to tell a node to send all its queued messages and block it from sending more. | COMPRESS, pbcast.FLUSH |
There are a number of files associated with the cluster, it seems the latest version of JBoss has renamed some of the files (from version 4 to version 5) and split them up abit I have commented on these below. Most of the configuration files are in server/all/deploy/cluster
| Service | Configuration files |
| Main configuration file (HAPartition) | server/all/deploy/cluster/cluster-jboss-beans.xml (old version) server/all/deploy/cluster/hapartition-jboss-beans.xml (latest version) server/all/deploy/cluster/ha-legacy-jboss.xml (latest version) |
| JGroups protocol stack | jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml Note: this is were you can change the IP address and multicast port numbers. |
| Session bean load balancing | jboss-cluster-beans.xml (old version) hapartition-jboss-beans.xml (latest version) ha-legacy-jboss.xml (latest version) EJB annotations (in your session bean) |
| SFSB replication | jgroups-channelfactory.sar/META-INF/jboss-cache-configs.xml jgroups-channelfactory.sar/META-INF/jboss-cache-manager-jboss-beans.xml |
| Entity cache replication | jgroups-channelfactory.sar/META-INF/jboss-cache-configs.xml jgroups-channelfactory.sar/META-INF/jboss-cache-manager-jboss-beans.xml |
| HTTP session replication and passivation | jgroups-channelfactory.sar/META-INF/jboss-cache-configs.xml jgroups-channelfactory.sar/META-INF/jboss-cache-manager-jboss-beans.xml server/all/deployers/jbossweb.deployer/META-INF/war-deployers-jboss-beans.xml WEB-INF/web.xml WEB-INF/jboss-web.xml |
| High availability naming service | cluster-jboss-beans.xml (old version) hapartition-jboss-beans.xml (latest version) ha-legacy-jboss.xml (latest version) |
| JNDI HA | server/all/deploy/cluster/hajndi-jboss-beans.xml |
The hapartition-jboss-beans.xml configuration gives the name to the cluster and also sets up the cache manager it uses annotations to do this. The cache manager bean points to a JChannelFactory which manages the single multiplex channel that JBoss provides and makes the protocol stacks available look for the <jgroupsConfig multiplexerStack> to which one it is using. The channelfactory contains a number of protocols that you can use udp, udp-async, shared-udp, tcp, etc.
There are not too many files here so I suggest that you have a look at them and piece them together the order would be partition -> cache -> channels
JBoss enables state replication using JBoss cache a distributed cache built on top of JGroups, it can replicate many types of objects
Distributed caches means that if any of the nodes local caches are updated it is copied to the other nodes in the cluster, the number of nodes that the cache is replicated is dependent on what you setup (total or buddy replication). There are a number of files that setup the cache
| Replicated Cache | Configuration File |
| HA Partition cache | deploy/cluster/hapartition-jboss-beans.xml Note: this is where you setup either total or buddy replication |
| Stateful session bean cache | deploy/ejb3.interceptors-aop.xml |
| Entity bean cache | deployers/ejb3.deployer/META-INF/persistence.properties |
| HTTP session cache | deployers/jboss.deployer/META-INF/war-deployers-jboss-bean.xml |
| HTTP single-sign-on cache | jgroups-channelfactory.sar/META-INF/jboss-cache-manager-jboss-beans.xml |
There are a number of cache configurations that you can change the most common ones are below
| MultiplexerStack | This points to the JGroups protocol stack that the cache should use to communicate with other nodes when replicating. |
| BuddyReplicationConfig | this enables you to specify the number of buddies that a node should have, define a communication timeout and more |
| IsolationLevel | can be used to set the transaction isolation level for updates to the distributed cache. The isolation levels are
Note: serializable will give you the best protecting but the worst performance, thus none will give you the least protection but the best performance |
| CacheMode | specifies the strategy that the cache uses for replicating with other nodes in the cluster
|
| CacheLoaderConfig | defines a cache loader for the cache, the cache loader is a component of the caching framework that knows how to read and write the data in a cache and from a secondary datastore (database, filesystem). |
| EvictionPolicyConfig | specifies the eviction policy for the cache, there are a number of different policies you can use
Note: you can break up the cache so that each region can specify its own configuration for the eviction policy, allowing for different frequencies. The default region is called _default_. |
Caches are particular good for data that's often used but seldom changes, try not to cache data that is changing all the time, also try not to cache data that applications use that are not participating in the distributed cache, the cache hit/miss ratio becomes much less predictable and the cache becomes less reliable.