Oracle Database Architecture overview
There are two terms that are used with Oracle
These two are very closely related but a database can be mounted and opened by many instances. An instance may mount and open only a single database at any one point in time.
The File Structure
The are a number of different file types that make up a database
In order for Oracle to start it needs some basically information, this information is supplied by using a parameter file. The parameter file can be either a pfile or a spfile:
The parameter file for Oracle is the commonly know file init.ora or init<oracle sid>.ora, the file contains key/value pairs of information that Oracle uses when starting the database. The file contains information such as database name, caches sizes, location of control files, etc.
By Default the location of the parameter file is
The main difference between the spfile and pfile is that instance parameters can be changed dynamically using a spfile, where as you require a instance reboot to load pfile parameters.
To convert the file from one of the other you can perform the following
| create pfile using a spfile | create pfile='c:\oracle\pfile\initD10.ora' from spfile; |
| startup db using pfile | startup pfile='c:\oracle\pfile\initD10.ora'; |
| create spfile using a pfile | create spfile from pfile='c:\oracle\pfile\initD10.ora'; |
| Display spfile location | show parameter spfile |
By Default Oracle will create at least two data files, the system data file which holds the data dictionary and sysaux data file which non-dictionary objects are stored, however there will be many more which will hold various types of data, a data file will belong to one tablespace only (see tablespaces for further details).
Data files can be stored on a number of different filesystem types
Data files contain the following
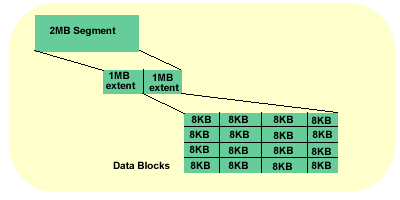
The relationship between segments, extents and blocks looks like this
The parameter DB_BLOCK_SIZE determines the default block size of the database. Determining the block size depends on what you are going to do with the database, if you are using small rows then use a small block size (oracle recommends 8KB), if you are using LOB's then the block size should be larger.
| 2KB or 4KB | OLTP - online transaction processing database would benefit from a small block size |
| 8KB (default) | Most databases would be OK to use the default size |
| 16KB or 32KB | DW - data warehouses, media database would benefit from a larger block size |
Notes |
|
You can have different block sizes within the database, each tablespace having a different block size depending on what is stored in the tablespace. For an example System tablespace could use the default 8KB and the OLTP tablespace could use a block size of 4KB. There are few parameters that cannot be changed after installing Oracle and the DB_BLOCK_SIZE is one of them, so make sure to select the correct choice when installing Oracle. |
|
A data block will be made up of the following, the two main area's are the free space and the data area.
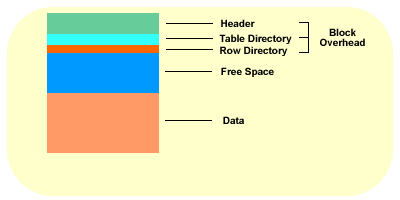
| Header | contains information regarding the type of block (a table block, index block, etc), transaction information regarding active and past transactions on the block and the address (location) of the block on the disk |
| Table Directory | contains information about the tables that store rows in this block |
| Row Directory | contains information describing the rows that are to be found on the block. This is an array of pointers to where the rows are to be found in the data portion of the block. |
| Block overhead | The three above pieces are know as the Block Overhead and are used by Oracle to manage the block itself. |
| Free space | available space within the block |
| Data | data within the block |
A tablespace is a container which holds segments. Each and every segment belongs to exactly one tablespace. Segments never cross tablespace boundaries. A tablespace itself has one or more files associated with it. An extent will be contained entirely within one data file.
So in summary the Oracle hierarchy is as follows:
The minimum tablespaces required are the system and sysaux tablespace, the following reasons are why tablespaces are used.
There are a number of types that a tablespace can be
See tablespaces for detailed information regarding creating, resizing, etc
Oracle will use temporary files to store results of a large sort operations when there is insufficient memory to hold all of it in RAM. Temporary files never have redo information (see below) generated for them, although they have undo information generated which in turns creates a small amount of redo information. Temporary data files never need to be backed up ever as they cannot be restored.
All the Oracle changes made to the db are recorded in the redo log files, these files along with any archived redo logs enable a dba to recover the database to any point in the past. Oracle will write all committed changes to the redo logs first before applying them to the data files. The redo logs guarantee that no committed changes are ever lost. Redo log files consist of redo records which are group of change vectors each referring to specific changes made to a data block in the db. The changes are first kept in the redo buffer but are quickly written to the redo log files.
There are two types of redo log files online and archive. Oracle uses the concept of groups and a minimum of 2 groups are required, each group having at least one file, they are used in a circular fashion when one group fills up oracle will switch to the next log group.
See redo on how to configure and maintain the log files.
When a redo log file fills up and before it is used again the file is archived for safe keeping, this archive file with other redo log files can recover a database to any point in time. It is best practice to turn on ARCHIVELOG mode which performs the archiving automatically.
See redo on how to enable archiving and maintain the archive log files.
When you change data you should be able to either rollback that change or to provide a read consistent view of the original data. Oracle uses undo data (change vectors) to store the original data, this allows a user to rollback the data to its original state if required. This undo data is stored in the undo tablespace. See undo for further information.
The control is one of the most important files within Oracle, the file contains data and redo log location information, current log sequence numbers, RMAN backup set details and the SCN (system change number - see below for more details). This file should have multiple copies due to it's importance. This file is used in recovery as the control file notes all checkpoint information which allows oracle to recover data from the redo logs. This file is the first file that Oracle consults when starting up.
The view V$CONTROLFILE can be used to list the controlfiles, you can also use the V$CONTROLFILE_RECORD_SECTION to view the controlfile's record structure.
You can also log any checkpoints while the system is running by setting the LOG_CHECKPOINTS_TO_ALERT to true.
See recovering critical files for more information.
This file optional and contains the names of the database users who have been granted the special SYSDBA and SYSOPER admin privilege.
The alert.log file contains important startup information, major database changes and system events, this will probably be the first file that will be looked at when you have database issues. The file contains log switches, db errors, warnings and other messages. If this file is removed Oracle creates another one automatically.
Traces files are debugging files which can trace background process information (LGWR, DBWn, etc), core dump information (ora-600 errors, etc) and user processing information (SQL).
The OMF feature aims to set a standard way of laying out Oracle files, there is no need to worry about file names and the physical location of the files themselves. The method is suited in small to medium environments, OMF simplifies the initial db creation as well as on going file management.
System Change (Commit) Number (SCN)
The SCN is an important quantifier that oracle uses to keep track of its state at any given point in time. The SCN is used to keep track of all changes within the database, its a logical timestamp that is used by oracle to order events that have occurred within the database. SCN's are increasing sequence numbers and are used in redo logs to confirm that transactions have been committed, all SCN's are unique. SCN's are used in crash recovery as the control maintains a SCN for each data file, if the data files are out of sync after a crash oracle can reapply the redo log information to bring the database backup to the point of the crash. You can even take the database back in time to a specific SCN number (or point in time).
Checkpoints are important events that synchronize the database buffer cache and the datafiles, they are used with recovery. Checkpoints are used as a starting point for a recovery, it is a framework that enables the writing of dirty blocks to disk based on a System Change or Commit Number (for SCN see above) and a Redo Byte Address (RBA) validation algorithm and limits the number of blocks to recover.
The checkpoint collects all the dirty buffers and writes them to disk, the SCN is associated with a specific RBA in the log, which is used to determine when all the buffers have been written.