Sun Cluster 3.2 - Introduction
This web page is a brief introduction into Sun Cluster 3.2, I already discussed Sun Cluster 3.1 and many topics that I will be discussing will overlap.
The below web pages make up a series that you can follow, these pages will be as brief as possible and will guide you on how to install, configure and manage Sun Cluster 3.2
First a introduction to the Sun Cluster 3.2 system, a cluster consist of two or more nodes, that work together in a single continuously available system to provide applications, system resources and data to end users. Each node in a cluster is a fully functional standalone system but when in a cluster the nodes will communicate via a interconnect and work together as a single entity to provide increased availability and performance, however this does come with additional costs.
The biggest decision to make it that does the application need to be clustered, you can quite easily make a single server high available by making all SPOF (Single Points Of Failure) are eliminated (additional power, power supplies, disk mirroring, etc). This setup would be more than adequate for most Enterprise applications. However there are times when the additional cost of a cluster solution can be justified.
In a cluster environment a node failure, will not disrupt a service (there maybe a slight pause), the cluster is designed to handle node failures and to response quickly, sometimes the end users will not notice. The old argument with having a cluster was that one node was not used, this being the node that would take over if another node in the cluster was to fail, this deemed to be expensive waste of resources, however now days you can run applications in parallel and as long as one node can handle all the applications (you may have slight performance degradation when doing so) you can utilize both or all nodes in the cluster.
When using a cluster and data is involved, you make sure that all nodes can access the shared data disks, this means that all nodes can take over the application (or database) and are working with the same set of disks the failed node was working with.
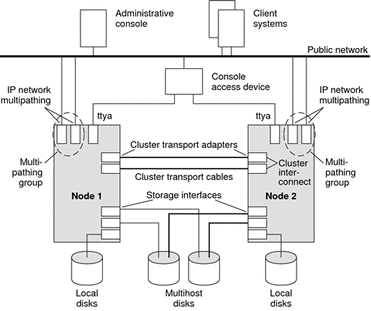
Below is a diagram of a Sun cluster setup, both nodes have IP network multipathing, they both access to the data disks (multihost disks), and both have cluster interconnect network which is used by the nodes to talk to each other.
There are a number of key concepts in Sun Cluster 3.2, I have a table below that lists them
| Cluster Nodes | A node is a single server within a cluster, you can have up to 16 nodes within a single cluster. All nodes within a cluster have the capacity to talk to each other (via the interconnect), when a node joins or leaves a cluster all other nodes are made aware. Nodes should be of a similar build (same CPU, Memory, etc) but they do not have to be. |
| Cluster Interconnect | The interconnect should be a private network that all cluster nodes are connected to, the nodes communicate across this network sharing information about the cluster. The interconnect should have redundancy built in thus it should be able to survive network outages |
| Cluster Membership Monitor (CMM) | The cluster membership monitor (CMM) is a distributed set of agents that exchange messages over the interconnect to perform the following
The CMM uses heartbeats across the interconnect for any changes to the cluster membership, if it detects change, it initializes a cluster reconfiguration to renegotiate cluster membership. To determine membership the CMM performs the following
|
| Cluster Configuration Repository (CCR) | The CCR is a private, cluster-wide, distributed database for storing information that pertains to the configuration and state of the cluster. All nodes will have a consistent view of this database and is updated when the cluster is changed. The CCR will contain the following information
|
| Fault Monitors | There are a number of monitors that are constantly monitoring the cluster and detecting faults, the cluster is monitoring applications, disks, network, etc.
|
| Quorum Devices | A quorum device is a shared storage device (quorum) that is shared by the nodes and contribute votes that are used to establish a quorum. The cluster will only operate when a quorum is available, it is used when a cluster is partitioned into separate sets of nodes to establish which set of nodes constitutes the new cluster. Both nodes and devices have a vote to form a quorum |
| Devices | The globaldevice filesystem is shared among all nodes in the cluster, this allows access to a device from anywhere in the cluster (access disks on another node even if it is not physically attached). Global devices can be disks, cd-rom's, tape drives, the cluster assign a unique ID to each device via the device ID driver (DID). The DID probes all nodes in the cluster and builds a list of unique disk devices, it also assigns a major:minor number of each device so that it is consistent across all nodes. |
| Data Services | A data service may be a Apache server or a Oracle database, the cluster will manage the resource and its dependencies and it will be under the control of the Resource Group Manager (RGM). The RGM will perform the following
The RGM handles resources and there are many different types
Resources are then grouped based on a data service, for example all the application, data disks, networking is grouped into a data service (application service), dependencies can be used between the resources, in other words don't start Oracle if the disks are not available. There are a number data service types, depending on what you require
|
Before moving on to the architecture I want to discuss data integrity, this becomes more important in a cluster as a number of nodes will be sharing the data, a cluster must never split into separate partitions that are active at the same time, this will lead to data corruption. There are two types of problems when a cluster splits
The quorum is used to resolve cluster splitting problems, by using the votes the cluster can identify when partition is the real cluster, the quorum resolves the above problems in the following way
| Split Brain | Enable only the partition (subcluster) with a majority of votes to run as the cluster (only one partition can exist), after a node loses the race for the quorum, that node will be force to panic (failure fencing). |
| Amnesia | Guarantees that when a cluster is booted, it has at least one node that was a member of the most recent cluster membership and thus has the latest configuration data. |
I spoke about the split brain problem above and how the quorum is used to resolve this issue and prevent data corruption, I want to discuss failure fencing which limits node access to multihost disks by prevent access to the disks, when a node leaves the cluster failure fencing ensures that the node can no longer access the disks, only current nodes in the cluster can have access. The cluster system uses SCSI disk reservation to implement failure fencing, using SCSI reservation failed nodes are "fenced" away from the multihost disks, preventing them from accessing those disks. When a problem is detected it initiates a failure-fencing procedure to prevent the failed node accessing the disks by panic'ing the node and issuing a "reservation conflict" message on its display, if the node reboots it is not allowed to rejoin the cluster until all issues have been resolved.
Sun Cluster 3.2 architecture has not changed much from version 3.1, the diagram above is a classic cluster setup, the minimum you will need to obtain a supported cluster environment. The trickiest part of building a cluster is setting up the shared disks whether you use a SAN or JBOD you should make sure they are dual-pathed and high available, protecting your data is the most important aspect when clustering your application.
To function as a cluster member you must have the following software installed
The diagram below details the software components that make up the cluster solution,
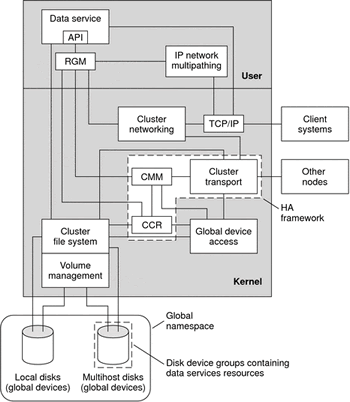
I have a brief description of some of the components:
The Cluster Membership Monitor (CMM) ensures that data is safe from corruption, all nodes must reach a consistent agreement on the cluster membership, the CMM coordinates a reconfiguration when the cluster changes in response to failures, the CMM uses the transport to send and receive messages regarding reconfiguration changes to other nodes. The CMM runs entirely in the kernel.
The Cluster Configuration Repository (CCR) relies on the CMM to guarantee that a cluster is running only when the quorum is established. The CCR is responsible for verifying data consistency across the cluster, performing recovery as necessary and facilitating updates to the data.
The cluster filesystem is the proxy between the following
The cluster uses global devices (disks, tapes, cd-roms) to access devices throughout the cluster, all nodes will have access to these devices using the same filename (/dev/global/) even if it does not have a physical connection.
The cluster can offer salability to data services, by using load-balancing it can distribute requests amongst a number of nodes, thus distributing the load. It is pretty much standard load balancing and uses two different classes called pure and sticky.
| Pure | is where any instance can respond to client requests |
| Sticky | is where only the first node to respond will be the only node to deal with the request. The sticky service has a further two options
|
The Cluster-Interconnect components, you must have at least two private interconnects (redundancy) but you can have up to six, you can use fast ethernet, gigabit-ethernet or infiniband. The cluster interconnect consists of the following
| Adapters | The physical network card/adaptor |
| Switches | The switches are also called Junctions, that reside outside the cluster. Switches perform pass through and switching functions to enable you to connect two or more nodes together. If you have a two nodes setup you can use cross-over cables instead. |
| Cables | These are the physical cables that connect the nodes to the switches or other nodes. |

It is advisable to configure IP multipathing groups, each group has one or more public network adaptors, the adaptors can be in either been in a active or standby state. Should a network or network cable fail the other adaptor in the group will take over as if nothing happened. Again this is a cost issue as you need more network adaptors, cables switches but i believe this to be a worthy investment and is a small cost compared to the cluster as a whole.
One final note about the network, is that you should keep private and public interfaces separate, and on different network switches, private interfaces should definitely be on its own network as it can interfere with the communication between the nodes, however I myself do create a 3 rd private interconnect connection across the public network just in case both private interconnect networks fail but only use this network if the other private fail.
Cluster 3.2 limitations are below