I mentioned above Cache Fusion in my GRD section, here I go into great detail on how it works, I will also provide a number of walk through examples on my RAC system.
Cache Fusion uses the most efficient communications as possible to limit the amount of traffic used on the interconnect, now you don't need this level of detail to administer a RAC environment but it sure helps to understand how RAC works when trying to diagnose problems. RAC appears to have one large buffer but this is not the case, in reality the buffer caches of each node remain separate, data blocks are shared through distributed locking and messagingoperations. RAC copies data blocks across the interconnect to other instances as it is more efficient than reading the disk, yes memory and networking together are faster than disk I/O.
Ping
The transfer of a data block from instances buffer cache to another instances buffer cache is know as a ping. As mentioned already when an instance requires a data block it sends the request to the lock master to obtain a lock in the desired mode, this process is known as blocking asynchronous trap (BAST). When an instance receives a BAST it downgrades the lock ASAP, however it might have to write the corresponding block to disk, this operation is known as disk ping or hard ping. Disk pings have been reduce in the later versions of RAC, thus relaying on block transfers more, however there will always be a small amount of disk pinging. In the newer versions of RAC when a BAST is received sending the block or downgrading the lock may be deferred by tens of milliseconds, this extra time allows the holding instance to complete an active transaction and mark the block header appropriately, this will eliminate any need for the receiving instance to check the status of the transaction immediately after receiving/reading a block. Checking the status of a transaction is an expensive operation that may require access (and pinging) to the related undo segment header and undo data blocks as well. The parameter _gc_defer_time can be used to define the duration by which an instance deferred downgrading a lock.
Past Image Blocks (PI)
In the GRD section I mentioned Past Images (PIs), basically they are copies of data blocks in the local buffer cache of an instance. When an instance sends a block it has recently modified to another instance, it preserves a copy of that block, marking as a PI. The PI is kept until that block is written to disk by the current owner of the block. When the block is written to disk and is known to have a global role, indicating the presents of PIs in other instances buffer caches, GCS informs the instance holding the PIs to discard the PIs. When a checkpoint is required it informs GCS of the write requirement, GCS is responsible for finding the most current block image and informing the instance holding that image to perform a block write. GCS then informs all holders of the global resource that they can release the buffers holding the PI copies of the block, allowing the global resource to be released. You can view the past image blocks present in the fixed table X$BH
| PIs |
select state, count(state) from X$BH group by state;
Note: the state column with 8 is the past images. |
Cache Fusion I
Cache Fusion I is also know as consistent read server and was introduced in Oracle 8.1.5, it keeps a list of recent transactions that have changed a block.the original data contained in the block is preserved in the undo segment, which can be used to provide consistent read versions of the block.
In a single instance the following happens when reading a block
- When a reader reads a recently modified block, it might find an active transaction in the block
- The reader will need to read the undo segment header to decide whether the transaction has been committed or not
- If the transaction is not committed, the process creates a consistent read (CR) version of the block in the buffer cache using the data in the block and the data stored in the undo segment
- If the undo segment shows the transaction is committed, the process has to revisit the block and clean out the block (delay block cleanout) and generate the redo for the changes.
In an RAC environment if the process of reading the block is on an instance other than the one that modified the block, the reader will have to read the following blocks from the disk
- data block to get the data and/or transaction ID and Undo Byte Address (UBA)
- undo segment header block to find the last undo block used for the entire transaction
- undo data block to get the actual record to construct a CR image
Before these blocks can be read the instance modifying the block will have to write those's blocks to disk, resulting in 6 I/O operations. In RAC the instance can construct a CR copy by hopefully using the above blocks that are still in memory and then sending the CR over the interconnect thus reducing 6 I/O operations.
As from Oracle 8 introduced a new background process called the Block Server Process makes the CR fabrication at the holders cache and ships the CR version of the block across the interconnect, the sequence is detailed in the table below
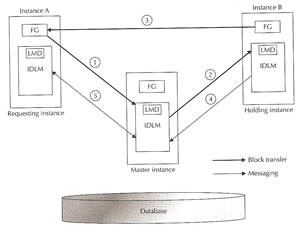 |
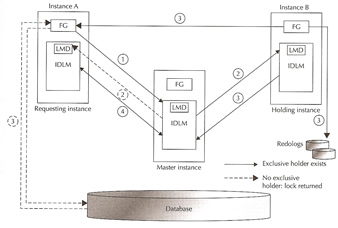
- An instance sends a message to the lock manager requesting a shared lock on the block
- Following are the possibilities in the global cache
- If there is no current user for the block, the lock manager grants the shared lock to the requesting instance
- if the other instance has an exclusive lock on the block, the lock manager asks the owning instance to build a CR copy and ship it to the requesting instance.
- Based on the result, either of the following can happen
- if the lock is granted, the requesting instance reads the block from disk
- The owning instance creates a CR version of the buffer in its own buffer cache and ships it to the requesting instance over the interconnect
- The owning instance also informs the lock manager and requesting instance that it has shipped the block
- The requesting instance has the locked granted, the lock manager updates the IDLM with the new holders of that resource
|
While making a CR copy, the holding instance may refuse to do so if
- it does not find any of the blocks needed in its buffer cache, it will not perform a disk read to make a CR copy for another instance
- It is repeatedly asked to send a CR copy of the same block, after sending the CR copies four times it will voluntarily relinquish the lock, write the block to the disk and let other instances get the block from the disk. The number of copies it will serve before doing so is governed by the parameter _fairness_threshold
Cache Fusion II
Read/Write contention was addressed in cache fusion I, cache fusion II addresses the write/write contention
 |
- An instance sends a message to the lock manager requesting an exclusive lock on the block
- Following are the possibilities in the global cache
- If there is no current user for the block, the lock manager grants the exclusive lock to the requesting instance
- if the other instance has an exclusive lock on the block, the lock manager asks the owning instance to release the lock
- Based on the result, either of the following can happen
- if the lock is granted, the requesting instance reads the block from disk
- The owning instance sends the current block to the requesting instance via the interconnect, to guarantee recovery in the event of instance death, the owning instance writes all the redo records generated for the block to the online redolog file. It will keep a past image of the block and inform the master instance that it has sent the current block to the requesting instance
- The lock manager updates the resource directory (GRD) with the current holder of the block
|
Cache Fusion in Operation
A quick recap of GCS, a GCS resource can be local or global, if it is local it can be acted upon without consulting other instances, if it is global it cannot be acted upon without consulting or informing remote instances. GCS is used as a messaging agent to coordinate manipulation of a global resource. By default all resources are in NULL mode (remember null mode is used to convert from one type to another (share or exclusive)).
The table below denotes the different states of a resource
| Mode/Role |
Local |
Global |
| Null (N) |
NL |
NG |
| Shared (S) |
SL |
SG |
| Exclusive (X) |
XL |
XG |
States |
| SL |
it can serve a copy of the block to other instances and it can read the block from disk, since the block is not modified there is no need to write to disk |
| XL |
it has sole ownership and interest in that resource, it has exclusive right to modify the block, all changes to the blocks are in the local buffer cache and it can write the block to the disk. If another instance wants the block it can to come via the GCS |
| NL |
used to protect consistent read block, if an instance wants it in X mode, the current instance will send the block to the requesting instance and downgrades its role to NL |
| SG |
a block is present in one or more instances, an instance can read the read from disk and serve it to other instances |
| XG |
a block can have one or more PIs, the instance with the XG role has the latest copy of the block and is the most likely candidate to write the block to the disk. GCS can ask the instance to write the block and serve it to other instances |
| NG |
after discarding PIs when instructed to by GCS, the block is kept in the buffer cache with NG role, this serves only as the CR copy of the block. |
Below are a number of common scenarios to help understand the following
- reading from disk
- reading from cache
- getting the block from cache for update
- performing an update on a block
- performing an update on the same block
- reading a block that was globally dirty
- performing a rollback on a previously updated block
- reading the block after commit
We will assume the following
- Four RAC environment (Instances A, B, C and D)
- Instance D is the master of the lock resource for the data block BL
- We will only use one block and it will reside at SCN 987654
- We will use a three-letter code for the lock states
- first letter will indicate the lock mode - N = Null, S = Shared and X = Exclusive
- second latter will indicate lock role - G = Global, L = Local
- The third letter will indicate the PIs - 0 = no PIs, 1 = a PI of the bloc
for example a code of SL0 means a global shared lock with no past images (PIs)
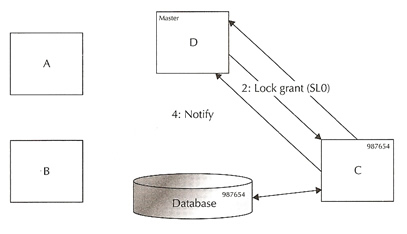
Reading a block from disk |
|
instance C want to read the block it will request a lock in share mode from the master instance
- Instance C requests the block by sending a shared lock request to master D
- The block has never been read into the buffer cache of any instance and it is not locked. Master D grants the lock to instance C. The lock granted is SL0 (see above to work out three-letter code)
- Instance C reads the block from the shared disk into its buffer cache
- Instance C has the block in shard mode, the lock manager updates the resource directory.
|
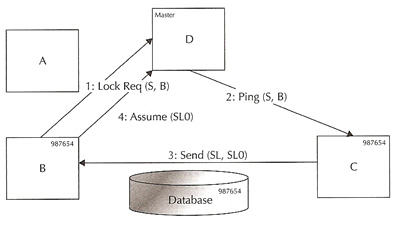
Reading a block from the cache |
|
Carrying on from the above example, Instance B wants to read the same block that is cached in instance C buffer.
- Instance B sends a shared lock request to master instance D
- The lock master knows that the block may be available at instance C and sends a ping message to instance C
- Instance C sends the block to instance B via the interconnect, along with the block instance C indicates that instance B should take the current lock mode and role from instance C, instance C keeps a copy of the block
- Instance B sends a message to instance D that it has assumed the SL lock for the block. This message is not critical for the lock manager, thus the message is sent asynchronously
|
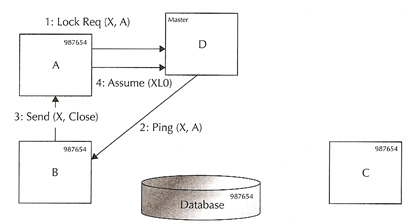
Getting a (Cached) clean block for update |
|
Carrying on from the above example, instance A wants to modify the same block that is already cached in instance B and C (block 987654)
- Instance A sends an exclusive lock request to master D
- The lock master knows that the block may be available at instance B in SCUR mode and at instance C in CR mode. it also sends a ping message to the shared lock holders. The most recent access was at instance B and instance D sends a BAST message to instance B
- Instance B sends the block to instance A via the interconnect and closes it shared lock. The block may still be in its buffer to be as CR, but all locks are released
- Instance A now has the exclusive lock on the block and sends an assume message to instance D, the lock is in XL0
- Instance A modifies the block in its buffer cache, the changes are not committed and thus the block has not been written to disk, thus the SCN remains at 987654
|
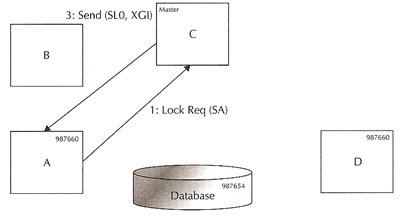
Getting a (Cached) modified block for update and commit |
|
Carrying on from the above example, instance C now wants to modify the block, if it tries to modify the same row it will have to wait until instance A either commits or rolls back. However in this case instance C wants to modify a different row in the same block.
- Instance C sends an exclusive lock request to master D
- The lock master knows that instance A holds an exclusive lock on the block and hence sends a ping message to instance A
- Instance A sends the dirty buffer to instance C via the interconnect, it downgrades the lock from XCR to NULL, it keeps a PI version of the block and disowns any lock on that buffer. Before shipping the block, Instance A has to create a PI image and flush any pending redo for the block change, the block mode on instance A is now NG1
- Instance C sends a message to instance D indicating it has the block in exclusive mode. The block role G indicates that the block is in global mode and if it needs to write the block to disk it must coordinate it with other instances that have past images (PIs) of that block. Instance C modifies the block and issues a commit, the SCN is now 987660.
|
Commit the previously modified block and select the data |
|
Carrying on from the above example, instance A now issues a commit to release the row level locks held by the transaction and flush the redo information to the redologs
- Instance A wants to commit the changes, commit operations do not require any synchronous modifications to the block
- The lock status remains the same as the previous state and change vectors for the commits are written to the redologs.
|
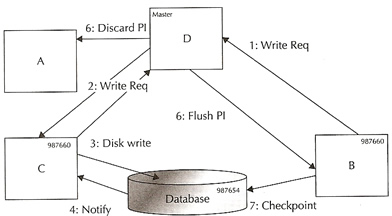
Write the dirty buffers to disk due to a checkpoint |
|
Carrying on from the above example, instance B writes the dirty blocks from the buffer cache due to a checkpoint (this is were it gets interesting and very clever)
- Instance B sends a write request to master D with the necessary SCN
- The master knows that the most recent copy of the block may be available at instance C and hence sends a message to instance C asking to write
- Instance C initiates a disk write and writes a BWR into the redolog file
- Instance C get the write notification that the write is complete
- Instance C notifies the master that the write is completed
- On receipt of the notification, instance D tells all PI holders to discard their PIs, and the lock at instance C writes the modified block to the disk
- All instances that have previously modified this block will also have to write a BWR. The write request by instance C has now been satisfied and instance C can now proceed with its checkpoint as usual
|
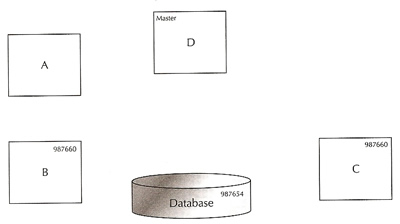
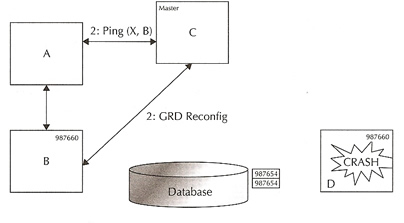
Master instance crashes |
|
Carrying on from the above example
- the master instance D crashes
- The Global Resource Directory is frozen momentarily and the resources held by master instance D will be equally distributed in the surviving nodes, also know as remastering (see remastering for more details).
|
Select the rows from Instance A |
|
Carrying on from the above example, now instance A queries the rows from that table to get the most recent data
- Instance A sends a shared lock to now the new master instance C
- Master C knows the most recent copy of the block may be in instance C and asks the holder to ship the CR block to instance A
- Instance C ships the CR block to instance A via the interconnect
|
The above sequence of events can be seen in the table below
Example |
Operation on Node |
Buffer Status |
A |
B |
C |
D |
A |
B |
C |
D |
1 |
|
|
read block from disk |
|
|
|
SCUR |
|
2 |
|
read the block from cache |
|
|
|
CR |
SCUR |
|
3 |
update the block |
|
|
|
XCUR |
CR |
CR |
|
4 |
|
|
update the same block |
|
PI |
CR |
XCUR |
|
5 |
commit the changes |
|
|
|
PI |
CR |
XCUR |
|
6 |
|
trigger checkpoint |
|
|
|
CR |
XCUR |
|
7 |
|
|
|
instance crash |
|
|
|
|
8 |
select the rows |
|
|
|
CR |
|
XCUR |
|