Architecture
Data is one, if not the main asset of a company, protection of data is vital to a DBA, this includes backing up and restoring in a timely manor. I am not going to lie but cost does play a big part in deciding if you can implement a particular solution, Oracle Data Guard may be overkill for most companies, having a up to the minute solution is not going come cheap, many smaller companies I have worked for were quite happy a having a simple copy the redo logs to a standalone machine then scripting a solution to apply those logs, maybe not the greatest solution but one that works. This does have its draw backs as it is a bespoke solution and generally not easy to manage or handover to other DBA's. Oracle's Data Guard is a well test and supported solution but it does not come cheap but it is a solution that is practically the same across all companies and one that all DBA's should be able to grasp very quickly when starting at a new company.
In this series I cover the architecture, installation and configuration of Oracle Data Guard 11g, I will also cover performance tuning and how to setup a solution to guarantee's zero data loss. I also cover how to use standby databases that are not used, thus getting he most out of your systems. I will also cover the new Enterprise Manager and how it integrates into Data Guard, more and more administration applications are using GUI interfaces, there is no getting away from it, my approach is to learn both as a GUI always will run the commandline option in the background and a good understanding of the commandline will help you track down and resolve difficult problems.
My own personal advise is have lots of practice at doing something, the more practice the better you will become at doing it and it will become second nature, in today's virtual world there are many virtual solutions (VMware, HyperV, etc) that you can setup and practice what ever you want, even some of these virtual solutions are free (VMware ESXi) all you need is a spare server or PC (see my virtual solution), some additional RAM and disk space. I can setup a similar solution to one that I have at a companies site and test and learn how that solution works and get a feel on what I need to do if I have to failover, I can practice and document the produces before it happens, in some cases I have been with a company and never had to failover but I am always glad that I did practice and have the documention ready to hand.
Ok that's enough of me rambling on, lets make a start on learning Oracle Data Guard.
Data Guard is basically a ship redo and then apply redo, as you know redo is the information needed to recover a database transaction. A production database referred to as a primary database transmits redo to one or more independent replicas referred to as standby databases. Standby databases are in a continuous state of recovery, validating and applying redo to maintain synchronization with the primary database. A standby database will also automatically resynchronize if it becomes temporary disconnected to the primary due to power outages, network problems, etc.
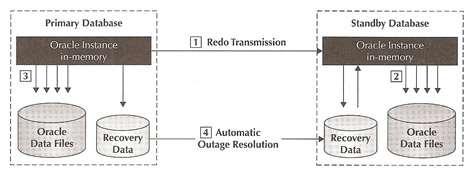
The diagram below shows the overview of Data Guard, firstly the redo transport services transmits redo data from the primary to the standby as it is generated, secondly services apply the redo data and update the standby database files, thirdly independently of Data Guard the database writer process updates the primary database files and lastly Data Guard will automatically resynchronize the standby database following power or network outages using redo data that has been archived at the primary.
If you have not read my Oracle series regarding redo here is a recap, a redo record (also know as a redo entry) is made up of a group of change vectors, each of which is a description of a change made to a single block in the database. Redo records contain all the information needed to reconstruct changes made to a database. During recovery the database will read the change vectors in the redo records and apply the changes to the relevant blocks.
Redo records are buffered in a circular fashion in the redo log buffer of the SGA, the log writer process (LGWR) is the background process that handles redo log buffer management. The LGWR at specific times writes redo log entries into a sequential file (online redo log file) to free space in the buffer, the LGWR writes the following
Remember that the LGWR can write to the log file using "group" commits, basically entire list of redo entries of waiting transactions (not yet committed) can be written to disk in one operation, thus reducing I/O. Even through the data buffer cache has not been written to disk, Oracle guarantees that no transaction will be lost due to the redo log having successfully saved any changes.
Data Guard Redo Transport Services coordinate the transmission of redo from the primary database to the standby database, at the same time the LGWR is processing redo, a separate Data Guard process called the Log Network Server (LNS) is reading from the redo buffer in the SGA and passes redo to Oracle Net Services from transmission to a standby database, it is possible to direct the redo data to nine standby databases, you can also use Oracle RAC and they don't all need to be a RAC setup. The process Remote File Server (RFS) receives the redo from LNS and writes it to a sequential file called a standby redo log file (SRL), the LNS process support two modes synchronous and asynchronous.
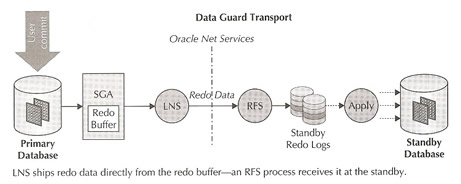
Synchronous |
|
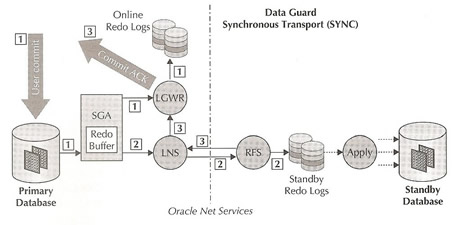
Synchronous transport (SYNC) is also referred to as "zero data loss" method because the LGWR is not allowed to acknowledge a commit has succeeded until the LNS can confirm that the redo needed to recover the transaction has been written at the standby site. In the diagram to the right the phases of a transaction are
This setup really does depend on network performance and can have a dramatic impact on the primary databases, low latency on the network will have a big impact on response times. The impact can be seen in the wait event "LNS wait on SENDREQ" found in the v$system_event dynamic performance view. There is also a timeout value that can be adjusted in the event of a network failure, we will discuss this in more detail in the installation section |
 |
Asynchronous |
|
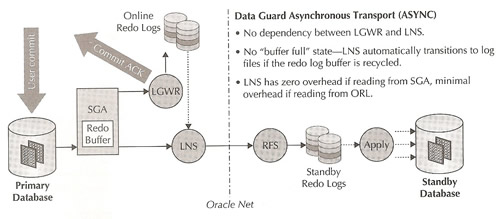
Asynchronous transport (ASYNC) is different from SYNC in that it eliminates the requirement that the LGWR waits for a acknowledgment from the LNS, creating a "near zero" performance on the primary database regardless of distance between the primary and the standby locations. The LGWR will continue to acknowledge commit success even if the bandwidth prevents the redo of previous transaction from being sent to the standby database immediately. If the LNS is unable to keep pace and the log buffer is recycled before the redo is sent to the standby, the LNS automatically transitions to reading and sending from the log file instead of the log buffer in the SGA. Once the LNS has caught up it then switches back to reading directly from the buffer in the SGA. The log buffer ratio is tracked via the view X$LOGBUF_READHIST a low hit ratio indicates that the LNS is reading from the log file instead of the log buffer, if this happens try increasing the log buffer size. The drawback with ASYNC is the increased potential for data loss, if a failure destroys the primary database before the transport lag is reduced to zero, any committed transactions that are part of the transport lag are lost. So again make sure that the network bandwidth is adequate and that you get the lowest latency possible. |
 |
Oracle recently released Advanced Compression option this new product contains several compression features, one of which is redo transport compression for Data Guard, it supports both SYNC and ASYNC. Like all compression tools it does have a impact on CPU resources but it will lower network bandwidth utilization.
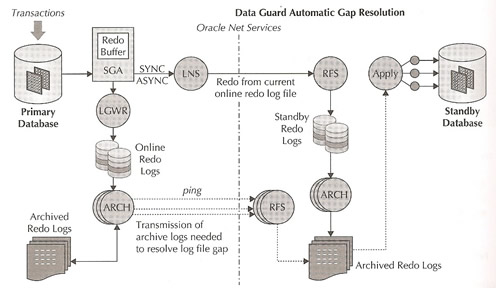
A log file gap occurs whenever a primary database continues to commit transactions while the LNS process has ceased transmitting redo to the standby database (network issues). The primary database continues writing to the current log file, fills it, and then switches to a new log file, then archiving kicks in and archives the file, before you know it there are a number of archive and log files that need to be processed by the the LNS basically creating a large log file gap. Data Guard uses an ARCH process on the primary database to continuously ping the standby database during the outage, when the standby database eventually comes back, the ARCH process queries the standby control file (via the RFS process) to determine the last complete log file that the standby received from the primary. The ARCH process will then transmit the missing files to the standby database using additional ARCH processes, at the very next log switch the LNS will attempt and succeed in making a connection to the standby database and will begin transmitting the current redo while the ACH processes resolve the gap in the background. Once the standby apply process is able to catch up to he current redo logs the apply process automatically transitions out of reading the archive redo logs and into reading the current SRL. The whole process can be seen in the diagram below
There are two methods in which to apply redo, Redo Apply (physical standby) and SQL Apply (logical standby). They both have the same common features:
Redo Apply |
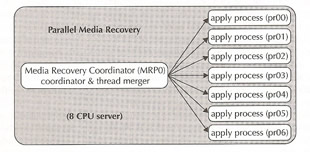
Redo apply is basically a block-by-block physical replica of the primary database, redo apply uses media recovery to read records from the SRL into memory and apply change vectors directly to the standby database. Media recovery does parallel recovery for very high performance, it comprises a media recovery coordinator (MRP0) and multiple parallel apply processes(PR0?). The coordinator manages the recovery session, merges the redo by SCN from multiple instances (if in a RAC environment) and parses redo into change mappings partitioned by the apply process. The apply processes read data blocks, assemble redo changes from mappings and then apply redo changes to the data blocks. This method allows you to be able to use the standby database in a read-only fashion, Active Data Guard solves the read consistency problem in previous releases by the use of a "query" SCN. The media recovery process on the standby database advances the query SCN after all dependant changes in a transaction have been fully applied. The query SCN is exposed to the user via the current_scn column of the v$database view. Read-only use will only be able to see data up to the query SCN and thus the standby database can be open in read-only mode while the media recovery is active, which make this an ideal reporting database.
You can use SYNC or ASYNC and is isolated from I/O physical corruptions, corruption-detections checks occur at the following key interfaces:
If Data Guard detects any corruption it will automatically fetch new copies of the data from the primary using gap resolution process in the hope of that the original data is free of corruption. The key features of this solution are
|
| SQL Apply (Logical Standby) |
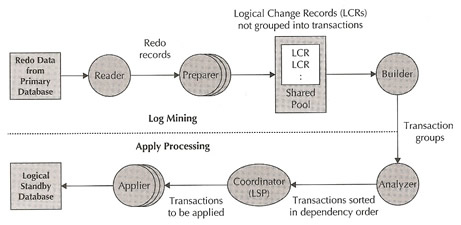
SQL apply uses the logical standby process (LSP) to coordinate the apply of changes to the standby database. SQL apply requires more processing than redo apply, the processes that make up SQL apply, read the SRL and "mine" the redo by converting it to logical change records and then building SQL transactions and applying SQL to the standby database and because there are more moving parts it requires more CPU, memory and I/O then redo apply
SQL apply does not support all data types, such as XML in object relational format and Oracle supplied types such as Oracle spatial, Oracle intermedia and Oracle text. The benefits to SQL apply is that the database is open to read-write while apply is active, while you can not make any changes to the replica data you can insert, modify and delete data from local tables and schemas that have been added to the database, you can even create materialized views and local indexes. This makes it ideal for reporting tools, etc to be used. The key features of this solution are
|
Note that if you have multiple standby databases you could use both solutions.
There are a number of protection modes available and depending on what you want to achieve, its even possible to hang your primary database if the standby database is uncontactable and you want maximum protection. Data Guard protection modes implement rules that govern how the configuration will respond to failures, enabling you to achieve your specific objectives for data protection, availability and performance. Data Guard can support multiple standby databases in a single configuration, they may or may not have the same protection mode settings depending on your requirements.
The protection modes are
| Maximum Performance | This mode requires ASYNC redo transport so that the LGWR process never waits for acknowledgment from the standby database, also note that Oracle no longer recommends the ARCH transport method in previous releases is used for maximum performance. Note that you will probably lose data if the primary fails and full synchronization has not occurred, the amount of data loss is dependant on how far behind the standby is is processing the redo. This is the default mode. |
| Maximum Availability | Its first priority is to be available its second priority is zero loss protection, thus it requires the SYNC redo transport. In the event that the standby server is unavailable the primary will wait the specified time in the NET_TIMEOUT parameter before giving up on the standby server and allowing the primary to continue to process. Once the connection has been re-established the primary will automatically resynchronize the standby database. When the NET_TIMEOUT expires the LGWR process disconnects from the LNS process, acknowledges the commit and proceeds without the standby, processing continues until the current ORL is complete and the LGWR cycles into a new ORL, a new LNS process is started and an attempt to connect to the standby server is made, if it succeeds the new ORL is sent as normal, if not then LGWR disconnects again until the next log switch, the whole process keeps repeating at every log switch, hopefully the standby database will become available at some point in time. Also in the background if you remember if any archive logs have been created during this time the ARCH process will continually ping the standby database waiting until it come online. You might have noticed there is a potential loss of data if the primary goes down and the standby database has also been down for a period of time and here has been no resynchronization, this is similar to Maximum Performance but you do give the standby server a chance to respond using the timeout. |
| Maximum Protection | The priority for this mode is data protection, even to the point that it will affect the primary database. This mode uses the SYNC redo transport and the primary will not issue a commit acknowledgment to the application unless it receives an acknowledgment from at least one standby database, basically the primary will stall and eventually abort preventing any unprotected commits from occurring. This guarantees complete data protection, in this setup it is advised to have two separate standby databases at different locations with no Single Point Of Failures (SPOF's), they should not use the same network infrastructure as this would be a SPOF. |
Data Guard uses two terms when cutting over the standby server, switchover which is a planned and failover which a unplanned event
| switchover | Switchover is a planned event, it is ideal when you might want to upgrade the primary database or change the storage/hardware configuration (add memory, cpu networking), you may even want to upgrade the configuration to Oracle RAC. What happens during a switchover is the following
The the new standby database (old primary) starts to receive the redo records and continues process until we switch back again. It is important to remember that both databases receive the EOR record so both databases know the next redo that will be received. Although you can have users still connecting to the primary database while the switchover occurs (which generally takes about 60 seconds) I personal have a small outage just to be on the safe side and just in case things don't go as smoothly as I hoped. You can even switch over form a linux database to a windows database from a 64 bit to a 32 bit database which is great if you want to migrate to a different O/S of 32/64 bit architecture, also your rollback option is very easy simply switchback if it did not work. |
| failover (manual or automatic) |
failover is a unplanned event, this is were the EOR was never written by the primary database, the standby database process what redo it has then waits, data loss now depends on the protection mode in affect (see above for protection modes).
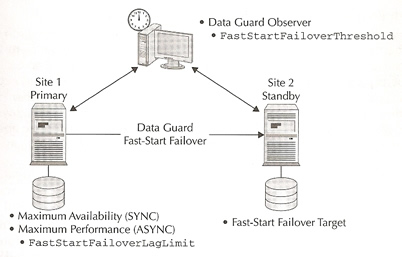
You have the option to manually failover or make the whole process automatic, manual gives you the DBA maximum control over the whole process obliviously the the length time of the outage depends on getting the DBA out of bed and failing over. Otherwise Oracle Data Guard Fast-Start Failover feature can automatically detect a problem and failover automatically for you. The failover process should take between 15 to 25 seconds.
|
One point to mention is regarding a split-brain scenario, where the primary and standby both think that they are the primary database, with Data Guard Fast-Start failover a failed primary cannot open without first receiving permission from the Data Guard observer process. The observer will know that a failover has occurred and will refuse to allow the original primary to open. The observer will automatically reinstate the failed primary as a standby for the new primary database making it impossible to have a split-brain condition.
You have three options on which to manage Data Guard
I order to use the Enterprise manager you must have a Data broker installed, the broker maintains the configuration files that includes profiles for all databases. Change can be propagated to all databases within the configuration, the broker also includes commands to start an observer, the process that monitors the status of a Data Guard configuration and executes an automatic failover. You might be think that the Data Guard broker is a single point of failure, which is incorrect, broker processes are background processes that exist on each database in the configuration and communicate with each other. if the system on which yo are attached fails, you simple attach to another database within the configuration and resume management from there.